要点
- 組合せ最適化問題を高速に解く新たなアニーリング処理モデルを構築
- このモデルにより全結合型アニーリングプロセッサLSIを世界で初めて開発
- 実応用性に優れ、従来比2桁以上のエネルギー効率改善を実現
概要
東京工業大学 科学技術創成研究院の本村真人教授らは、北海道大学、日立北大ラボ、東京大学と共同で、スマート社会においてますます重要となる組合せ最適化問題を高速に解くことができる新しいアニーリング処理方式と、それを利用した新しいプロセッサLSIの開発に成功した。
アニーリング処理は「局所型」よりも「全結合型」の方が応用範囲は格段に広い反面、高速に解くのが難しく、これまで全結合型のアニーリングプロセッサLSIは発表されていなかった。本研究では、全結合型のアニーリング処理を高速に解く新たなモデル「ストカスティック・セルラー・オートマタ(SCA)」を提案するとともに、このモデルを全並列・高速に実行するプロセッサアーキテクチャを開発し、世界初の全結合型アニーリングプロセッサLSI「STATICA」を実現した。STATICAは既存の手法に比べて、少なくともアニーリング処理の性能を数倍、エネルギー効率を2桁以上向上させることができる。
研究成果の詳細は2月17日から米国サンフランシスコで開催された「ISSCC2020(国際固体素子回路会議)」で発表された。
本研究開発は、
科学技術振興機構(JST) 戦略的創造研究推進事業 チーム型研究(CREST)
研究領域: |
「Society5.0を支える革新的コンピューティング技術」 |
研究総括: |
坂井修一(東京大学 大学院 情報理工学系研究科 教授) |
研究課題: |
「学習/数理モデルに基づく時空間展開型アーキテクチャの創出と応用」 |
研究代表者: |
本村真人(東京工業大学 科学技術創成研究院 教授/AIコンピューティング研究ユニット ユニット長) |
により推進されたものである。
また、日立北大ラボは、日立製作所と北海道大学が2016年6月に開設したオープンラボであり、北海道における少子高齢化や人口減少などの社会課題を解決し、地域創生につながる共同研究を推進している。
背景
組合せ最適化問題とは、さまざまなパラメータ(選び得る変数)の組合せの中からベストな解を選択する問題である[解説1]。交通、金融、製造・流通、化学・創薬・医療など、さまざまな分野の重要な問題が組合せ最適化問題に帰着することが知られているが、変数の数が多くなるにつれて、その組合せが爆発的に増大するため、従来型の計算機では効率的に解くことが難しい。
組合せ最適化問題の近似的な計算技法として、従来「アニーリング処理方式」[解説2]が用いられており、これを実現する計算システムはアニーリングマシンと呼ばれている。アニーリング処理には「局所型」と「全結合型」の二つのカテゴリー[解説3]があり、後者の方が応用範囲は格段に広い反面、高速に解くのが難しいことが知られている。このため、これまで全結合型のアニーリング処理を行うプロセッサLSIは存在していなかった[解説4]。
研究成果
本研究ではまず、組合せ最適化問題を高速に解くことができる新しいアニーリング処理モデル「ストカスティック(確率的)・セルラー・オートマタ」(Stochastic Cellular Automata:SCA)を構築した。従来のアニーリングマシンは基本的には「シミュレーテッド・アニーリング」(Simulated Annealing:SA)か、SAに類似する計算手法をベースにしていた。SAでは原理的に、ある疑似スピンの値が変わると、これとつながる全ての疑似スピンに与える影響を改めて計算する必要があった。このため、疑似スピンの値の更新は逐次的にならざるを得なかった(図1左)。これに対し、SCAでは全疑似スピンの値を並列に更新することができる(図1右)。
Clik here to view.
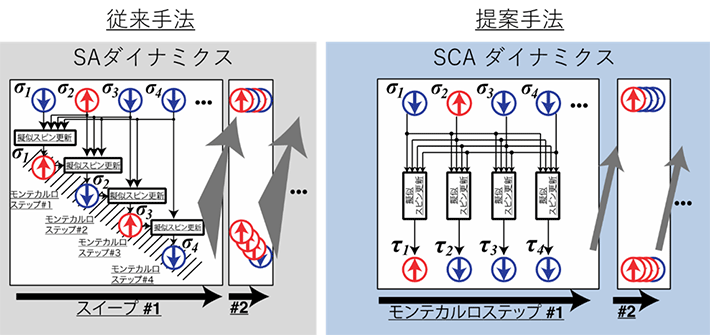
図1. SAとSCAの比較
研究チームは、このSCAによって、SAと同じ最適解を探せることを数学的に証明し、SCAを用いたアニーリングプロセッサLSIが実現可能であることを明らかにした。SCAにおける並列な疑似スピン更新は、更新したい疑似スピンにかかる相互作用係数を読み出し、現在の疑似スピンの値と演算することで行われる。この理解をもとに、相互作用係数をメモリに記憶させ、そのメモリから並列に相互作用係数を読み出し、メモリに付随したロジック回路で並列演算することで、SCAの計算を効率よく実行できることを発見した。このニアメモリ(メモリのすぐ近くで演算を行うことを指す言葉)型のアーキテクチャ(図2)を、「STATICA」(Stochastic Cellular Automata Annealer)と名付けた。
Clik here to view.
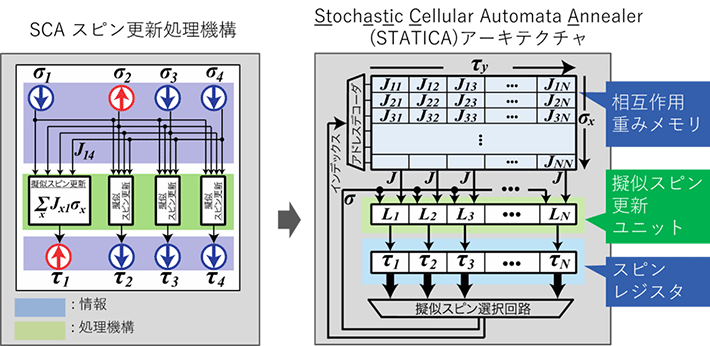
図2. STATICAアーキテクチャ
このアーキテクチャに基づいて、512疑似スピンの並列更新ができるように構成したアニーリングプロセッサLSI「STATICA」(図3)を開発した。これはTSMC社の65 nmプロセスで試作したチップであり、わずか3 mm×4 mmの大きさで512疑似スピンからなるイジングモデルのアニーリング処理を並列に実行できる。消費電力はわずか600 mW程度である。
Clik here to view.

図3. アニーリングプロセッサLSI:STATICA
近年、全並列型のアニーリングマシンが徐々に注目されるようになり、いくつかのマシンが提案されている。しかしSTATICA技術は図4のように、そうした既存技術と比べて、アニーリング速度、消費電力、答えの精度のいずれにおいても、非常に高い指標を達成することができる(少なくともアニーリング速度では数倍、エネルギー効率では2桁以上の向上)。
Clik here to view.
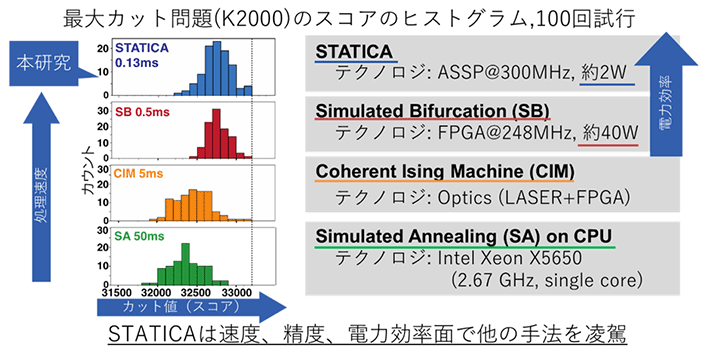
図4. STATICAと既存の全並列型アニーリングマシンの比較
(512疑似スピン対応のSTATICA試作チップから2000疑似スピン搭載STATICAチップの性能を外挿)
今後の展開
今回開発したSTATICA試作チップでは、オンチップの疑似スピン数が512個となっているが、STATICAのアーキテクチャ自体は疑似スピン数をスケーラブルに拡大し、より大規模な疑似スピンシステムでも並列更新を実現できることを特徴としている。今後は、社会に存在するさらに複雑で大規模な組合せ最適化問題を高速に解くトータルソリューションの実現を目指して、今回開発したチップのキャパシティ強化を進めていく。さらに、ディープラーニング・機械学習技術等を含む知識情報処理システム全体へのインテグレーションに取り組むことにより、このチップの早期の実用化を目指す。
解説
[解説1] 組合せ最適化問題の有名な例として、複数の都市をどの順番に回れば一番効率が良いかを決める「巡回セールスマン問題」がある。変数の数(都市の数)が多くなるとともに、その組合せが爆発的に増大するため、従来型の計算機では効率的に解くことが難しい。
[解説2] アニーリングとは、金属工学焼きなまし法(=時間をかけて冷却することで、金属原子の並び方を最適にする)に着想を得た組合せ最適化問題の近似的な計算技法。近年注目されている量子アニーリングは、極低温に冷却した際に現れる量子効果を用いてこのアニーリングを実現する方法である。本研究の成果は、量子効果に頼らずに、室温の一般的な集積回路の並列演算で、量子アニーリングを凌駕するアニーリング能力を実現できることを示唆している。
[解説3] アニーリング処理においては、まず、解くべき本来の組合せ最適化問題を、1または-1を取る二値の変数(疑似スピンと呼ばれる)の集合体とそれら疑似スピン間の相互作用群(イジングモデルと呼ばれる)に変換する。この際相互作用が、近接する疑似スピン間に限られているものを「局所型」、疑似スピンの集合全体の中に制限なく自由に相互作用を許すものを「全結合型」と呼ぶ。組合せ最適化問題をイジングモデルに変換する際に、局所型では十分な表現能力がないため、現実社会の複雑な問題に対応するのが難しいことが知られている。このため、全結合型のアニーリング処理を効率よく実行できるソリューションが求められている。
[解説4] 量子アニーリング分野でよく知られたD-Wave社のシステムは局所型であり、[解説3]で述べたように応用の難しさがあると言われている。一方、全結合型を狙った研究が主に日本の企業で活発に進められているが、FPGA(Field Programable Gate Array)やGPU(Graphics Processing Unit)をプログラムして実現するタイプの物である。CMOS集積回路を用いて作成された全結合型アニーリングを処理するプロセッサLSI(Large Scale Integrated Circuits)は、本発表が世界で初めてである。
発表情報
会議情報 : |
International Solid-State Circuits Conference (ISSCC) 2020, Feb., 17-19, San Francisco. |
論文タイトル : |
STATICA : A 512-Spin 0.25M-Weight Full-Digital Annealing Processor with a Near-Memory All-Spin-Update-at-Once Architecture for Combinatorial Optimization with Complete Spin-Spin Interactions |
発表責任者 : |
本村真人 |
- プレスリリース 組合せ最適化問題を高速に解く新しいアニーリングマシンを開発 ―世界初の全結合型アニーリングプロセッサLSIで高いエネルギー効率を実現―Image may be NSFW.
Clik here to view.![PDF]()
- AIコンピューティング研究ユニット
- 研究者詳細情報(STAR Search) - 本村真人 Masato Motomura
- 科学技術創成研究院 (IIR)
- 研究成果一覧

お問い合わせ先
東京工業大学 科学技術創成研究院
AIコンピューティング研究ユニット
教授 本村真人
E-mail : motomura@artic.iir.titech.ac.jp
Tel : 045-924-5654 / Fax : 045-924-5654
東京工業大学 広報・社会連携本部 広報・地域連携部門
E-mail : media@jim.titech.ac.jp
Tel : 03-5734-2975 / Fax : 03-5734-3661